Offline first
Çevrimdışı öncelikli(offline-first) bir uygulama, temel işlevselliğinin tamamını veya kritik bir alt kümesini internet erişimi olmadan gerçekleştirebilen bir uygulamadır. Yani, iş mantığının bir kısmını veya tamamını çevrimdışı olarak gerçekleştirebilir.
Çevrimdışı öncelikli bir uygulama oluşturmaya yönelik hususlar, uygulama verilerine ve business logic’e erişim sunan data katmanında başlar. Uygulamanın bu verileri zaman zaman cihaz dışındaki kaynaklardan yenilemesi gerekebilir. Bunu yaparken, güncel kalmak için ağ kaynaklarını kullanması gerekebilir.
Ağ kullanılabilirliği her zaman garanti edilmez. Cihazlarda genellikle ağ bağlantısının zayıf veya yavaş olduğu dönemler olabilir. Kullanıcılar aşağıdakilerle karşılaşabilir:
- Sınırlı internet bant genişliği
- Asansör veya tünelde olduğu gibi geçici bağlantı kesintileri.
- Ara sıra veri erişimi. Örneğin, yalnızca WiFi kullanan tabletler.
Nedeni ne olursa olsun, bir uygulamanın bu koşullarda yeterli şekilde çalışması genellikle mümkündür. Uygulamanızın çevrimdışı olarak doğru şekilde çalıştığından emin olmak için aşağıdakileri yapabilmelidir:
- Güvenilir bir ağ bağlantısı olmadan kullanılabilirliğini sürdürme.
- İlk ağ çağrısının tamamlanmasını veya başarısız olmasını beklemek yerine kullanıcılara yerel verileri hemen sunun.
- Pil ve veri durumunun bilincinde olacak şekilde veri alın. Örneğin, yalnızca şarj olurken veya WiFi’da olduğu gibi en uygun koşullarda veri getirme talebinde bulunarak. Yukarıdaki kriterleri karşılayabilen bir uygulama genellikle çevrimdışı öncelikli uygulama(offline-first app) olarak adlandırılır.
Design an offline-first app
Çevrimdışı öncelikli bir uygulama tasarlarken data katmanından ve uygulama verileri üzerinde gerçekleştirebileceğiniz iki ana işlemden başlamalısınız:
Reads: Kullanıcıya bilgi göstermek gibi uygulamanın diğer bölümleri tarafından kullanılmak üzere veri çekme.
Writes: User input’u daha sonra kullanmak üzere kalıcı hale getirme.
Veri katmanındaki repository‘ler, uygulama verilerini sağlamak için veri kaynaklarını birleştirmekten sorumludur. Çevrimdışı öncelikli bir uygulamada, en kritik görevlerini gerçekleştirmek için ağ erişimine ihtiyaç duymayan en az bir veri kaynağı olmalıdır. Bu kritik görevlerden biri de veri okumaktır.
Not: En azından, çevrimdışı öncelikli bir uygulama ağ erişimi olmadan okuma yapabilmelidir.
Model data in an offline-first app
Çevrimdışı öncelikli bir uygulama, ağ kaynaklarını kullanan her repository için en az 2 veri kaynağına sahiptir:
- Local veri kaynağı
- Network veri kaynağı
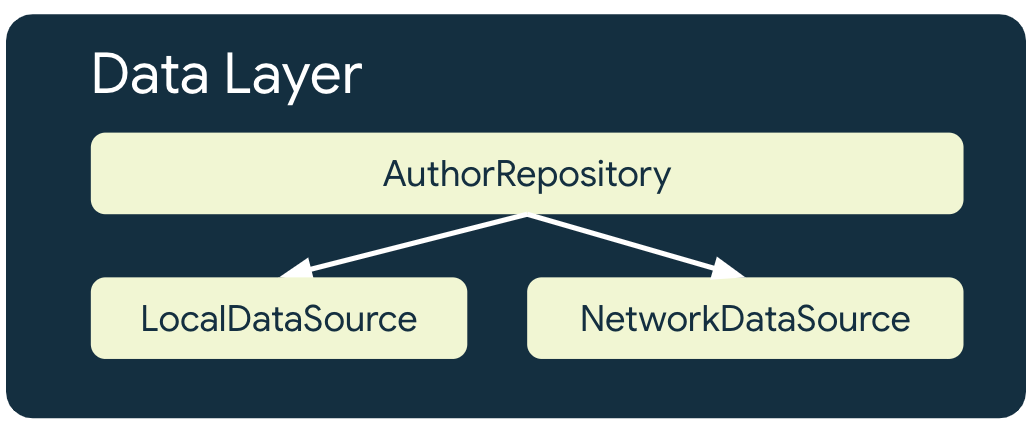
Not: Çevrimdışı öncelikli bir uygulamada ağ erişimi olan bir repository her zaman lokal bir veri kaynağına sahip olmalıdır.
The local data source
Lokal veri kaynağı, uygulama için standart haline gelmiş source of truth‘tır. Uygulamanın daha yüksek katmanlarının okuduğu tüm verilerin özel kaynağı olmalıdır. Bu, bağlantı durumları arasında veri tutarlılığı sağlar. Lokal veri kaynağı genellikle diske kalıcı olarak aktarılan bir depolama alanı tarafından desteklenir. Verileri diske kalıcı hale getirmenin bazı yaygın yolları şunlardır:
- Room gibi ilişkisel veritabanları gibi yapılandırılmış veri kaynakları.
- Yapılandırılmamış veri kaynakları. Örneğin, Datastore ile protocol buffers.
- Basit dosyalar
The network data source
Network veri kaynağı uygulamanın gerçek state’idir. Lokal veri kaynağı en iyi ihtimalle network veri kaynağı ile senkronize edilir. Bunun gerisinde de kalabilir, bu durumda uygulamanın tekrar çevrimiçi olduğunda güncellenmesi gerekir. Tersine, network veri kaynağı, bağlantı geri geldiğinde uygulama onu güncelleyene kadar lokal veri kaynağının gerisinde kalabilir. Uygulamanın domain ve UI katmanları asla network katmanı ile doğrudan bağlantı kurmamalıdır. Onunla iletişim kurmak ve lokal veri kaynağını güncellemek için onu kullanmak hosting repository’nin sorumluluğundadır.
Exposing resources
Lokal ve network veri kaynakları, uygulamanızın bunları nasıl okuyabileceği ve yazabileceği konusunda temel farklılıklar gösterebilir. Lokal bir veri kaynağını sorgulamak, SQL sorguları kullanmak gibi hızlı ve esnek olabilir. Buna karşılık, network veri kaynakları yavaş ve kısıtlı olabilir, örneğin RESTful kaynaklarına id ile artımlı olarak erişirken olduğu gibi. Sonuç olarak, her veri kaynağı genellikle sağladığı verilerin kendi temsiline ihtiyaç duyar. Bu nedenle lokal veri kaynağı ve network veri kaynağı kendi modellerine sahip olabilir.
Aşağıdaki dizin yapısı bu kavramı görselleştirmektedir. AuthorEntity, uygulamanın lokal veritabanından okunan bir yazarın temsilidir ve NetworkAuthor, network üzerinden serileştirilen bir yazarın temsilidir:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
AuthorEntity ve NetworkAuthor’un ayrıntıları aşağıdaki gibidir:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Hem AuthorEntity hem de NetworkAuthor’u veri katmanının içinde tutmak ve harici katmanların kullanması için üçüncü bir türü ortaya çıkarmak iyi bir pratiktir. Bu, harici katmanları, uygulamanın davranışını temelden değiştirmeyen lokal ve network veri kaynaklarındaki küçük değişikliklerden korur. Bu, aşağıdaki snippet’te gösterilmiştir:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Network modeli daha sonra bunu lokal modele dönüştürmek için bir extension metodu tanımlayabilir ve lokal model de benzer şekilde aşağıda gösterildiği gibi bunu harici temsile dönüştürmek için bir metoda sahiptir:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Not: Yukarıdaki gibi mapper’lar genellikle farklı modüllerde tanımlanan modeller arasında eşleme yapar. Sonuç olarak, tightly coupled modüllerden kaçınmak için bu mapperlari kullanıldıkları modüllerde tanımlamak genellikle faydalıdır. Daha fazla ayrıntı için modularization kılavuzuna bakın.
Reads
Okumalar, çevrimdışı öncelikli bir uygulamada uygulama verileri üzerindeki temel işlemdir. Bu nedenle, uygulamanızın verileri okuyabildiğinden ve yeni veriler mevcut olur olmaz uygulamanın bunları görüntüleyebildiğinden emin olmalısınız. Bunu yapabilen bir uygulama reaktif bir uygulamadır çünkü okuma API’lerini observable tiplerle sunarlar.
Aşağıdaki kod parçasında, OfflineFirstTopicRepository tüm okuma API’leri için Flow döndürür. Bu, network veri kaynağından güncellemeler aldığında okuyucularını güncellemesini sağlar. Başka bir deyişle, OfflineFirstTopicRepository’nin lokal veri kaynağı invalid edildiğinde değişiklikleri iletmesine olanak tanır. Bu nedenle, OfflineFirstTopicRepository’nin her okuyucusu, uygulamaya network bağlantısı yeniden sağlandığında tetiklenebilecek veri değişikliklerini ele almaya hazır olmalıdır. Ayrıca, OfflineFirstTopicRepository verileri doğrudan lokal veri kaynağından okur. Veri değişikliklerini okuyucularına ancak önce lokal veri kaynağını güncelleyerek bildirebilir.
class OfflineFirstTopicsRepository(
private val topicDao: TopicDao,
private val network: NiaNetworkDataSource,
) : TopicsRepository {
override fun getTopicsStream(): Flow<List<Topic>> =
topicDao.getTopicEntitiesStream()
.map { it.map(TopicEntity::asExternalModel) }
}
Not: Çevrimdışı öncelikli bir uygulamada repository’lerden okuma işlemleri doğrudan lokal veri kaynağından okunmalıdır. Herhangi bir güncelleme önce lokal veri kaynağına yazılmalıdır ve lokal veri kaynağı observable olduğu için tüketicilerini güncelleyecektir.
Error handling strategies
Çevrimdışı öncelikli uygulamalarda hataları ele almanın, oluşabilecekleri veri kaynaklarına bağlı olarak benzersiz yolları vardır. Aşağıdaki alt bölümlerde bu stratejiler özetlenmektedir.
- Local data source Lokal veri kaynağından okuma sırasında oluşan hatalar nadir olmalıdır. Okuyucuları hatalardan korumak için, okuyucunun veri topladığı Flow’larda catch operatörünü kullanın.
Bir ViewModel’de catch operatörünün kullanımı aşağıdaki gibidir:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Not: catch operatörü yalnızca exception’ın uygulamayı çökertmesini engeller, backing Flow yine de sonlanır. Exception’dan sonra flow’tan collecting’e devam etmek için retry metodunu kullanın.
- Network data source Bir network veri kaynağından veri okunurken hata oluşursa, uygulamanın veri getirmeyi yeniden denemek için bir heuristic yöntem kullanması gerekecektir. Yaygın heuristic yöntemler şunlardır:
Exponential backoff
Exponential backoff‘ta uygulama, başarılı olana veya diğer koşullar durması gerektiğini belirleyene kadar artan zaman aralıklarıyla network veri kaynağından okumayı denemeye devam eder.
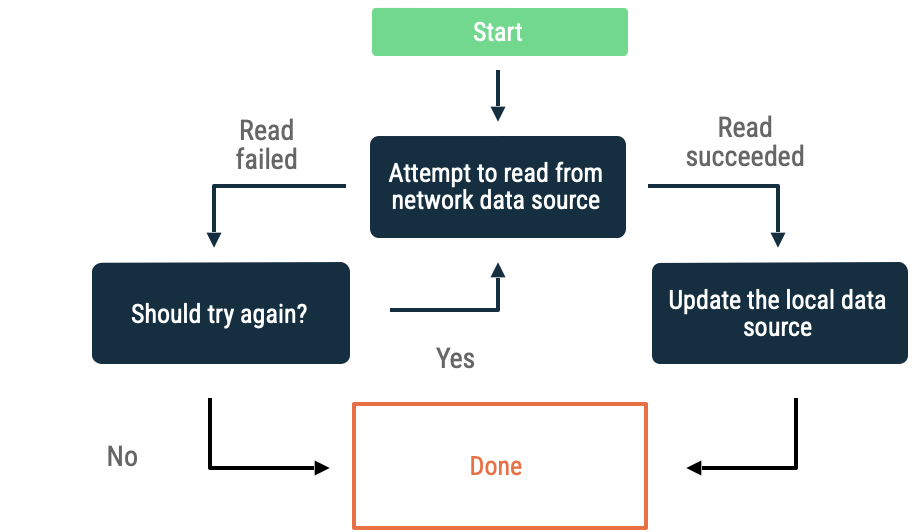
Uygulamanın backing off yapmaya devam edip etmeyeceğini değerlendirmek için kriterler şunlardır:
- Network veri kaynağının belirttiği hata türü. Örneğin, bağlantı eksikliğini gösteren bir hata döndüren network çağrılarını yeniden denemelisiniz. Tersine, uygun kimlik bilgileri mevcut olana kadar yetkilendirilmemiş HTTP isteklerini yeniden denememelisiniz.
- İzin verilen maksimum yeniden deneme sayısı.
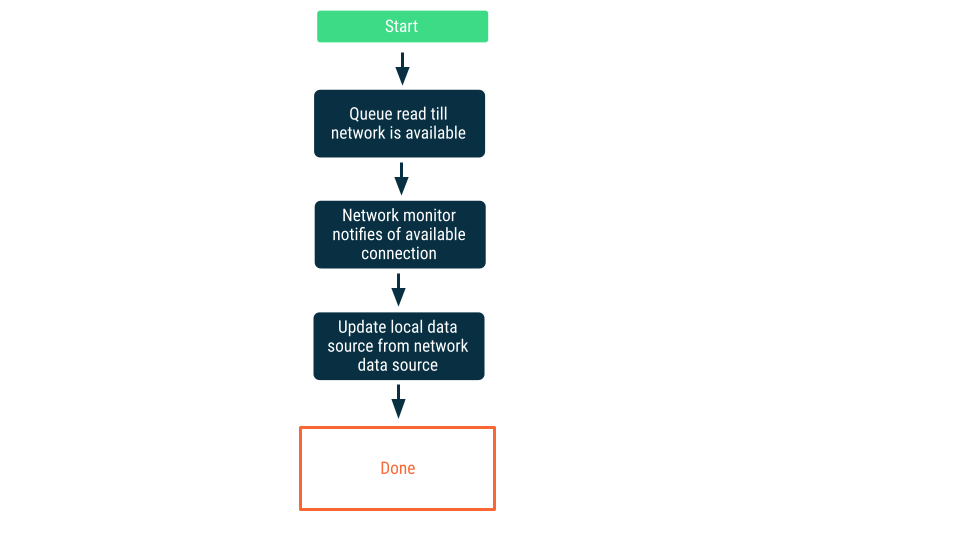
Network connectivity monitoring Bu yaklaşımda, uygulama network veri kaynağına bağlanabileceğinden emin olana kadar okuma istekleri kuyruğa alınır. Bağlantı kurulduktan sonra okuma isteği kuyruktan çıkarılır, veri okunur ve lokal veri kaynağı güncellenir. Android’de bu kuyruk bir Room veritabanı ile tutulabilir ve WorkManager kullanılarak kalıcı iş olarak tüketilebilir.
Writes
Çevrimdışı öncelikli bir uygulamada veri okumak için önerilen yol observable tipleri kullanmak olsa da, yazma API’leri için eşdeğer olan suspend fonksiyonları gibi asenkron API’lerdir. Bu, UI thread’inin engellenmesini önler ve çevrimdışı öncelikli uygulamalardaki yazma işlemleri bir network sınırını geçerken başarısız olabileceğinden hata ele almaya yardımcı olur.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
Yukarıdaki kod parçasında, yukarıdaki metot askıya aldığı için tercih edilen asenkron API Coroutines‘tir.
Write strategies
Çevrimdışı öncelikli uygulamalarda veri yazarken göz önünde bulundurulması gereken üç strateji vardır. Hangisini seçeceğiniz, yazılmakta olan veri türüne ve uygulamanın gereksinimlerine bağlıdır:
Online-only writes
Verileri network sınırı boyunca yazmayı deneyin. Başarılı olursa, lokal veri kaynağını günceller, aksi takdirde bir exception atar ve uygun şekilde yanıt vermeyi çağırana bırakır.
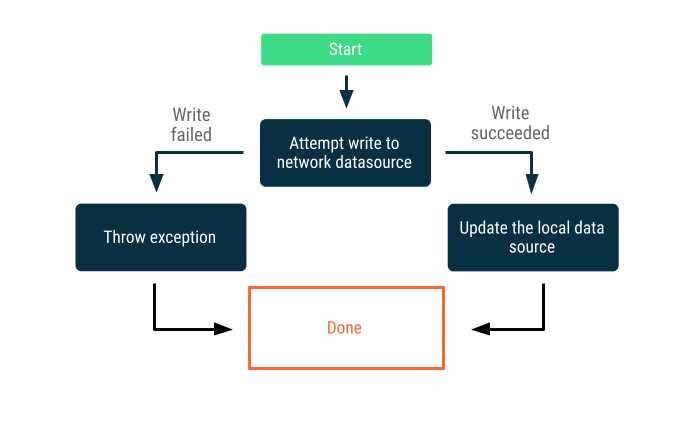
Bu strateji genellikle neredeyse gerçek zamanlı olarak çevrimiçi gerçekleşmesi gereken yazma işlemleri için kullanılır. Örneğin, bir banka transferi. Yazma işlemleri başarısız olabileceğinden, genellikle kullanıcıya yazmanın başarısız olduğunu bildirmek veya kullanıcının ilk etapta veri yazmaya çalışmasını önlemek gerekir. Bu senaryolarda kullanabileceğiniz bazı stratejiler şunları içerebilir:- Bir uygulama veri yazmak için internet erişimi gerektiriyorsa, kullanıcıya veri yazmasına izin veren bir UI sunmamayı veya en azından bunu devre dışı bırakmayı tercih edebilir.
- Kullanıcının çevrimdışı olduğunu bildirmek için kullanıcının reddedemeyeceği bir açılır mesaj veya geçici bir mesaj kullanabilirsiniz.
Queued writes
Yazmak istediğiniz bir nesne olduğunda, bunu bir kuyruğa ekleyin. Uygulama tekrar çevrimiçi olduğunda exponential back off ile kuyruğu tüketmeye devam edin. Android’de çevrimdışı bir kuyruğu tüketmek, genellikle WorkManager’a devredilen kalıcı bir iştir.
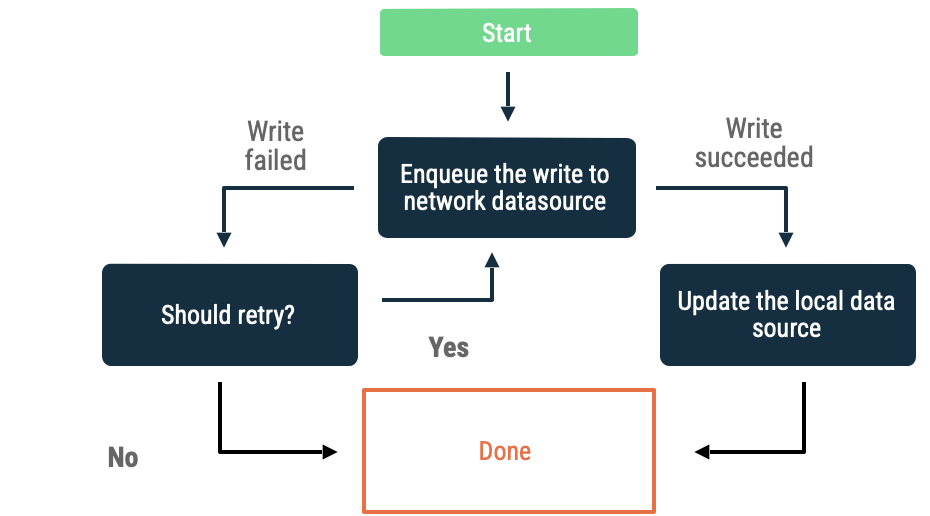
Bu yaklaşım aşağıdaki durumlarda iyi bir seçimdir:
- Verilerin ağa yazılması zorunlu değildir.
- İşlem zamana duyarlı değildir.
- İşlemin başarısız olması durumunda kullanıcının bilgilendirilmesi gerekli değildir.
Bu yaklaşımın kullanım alanları arasında analytics eventlar ve loglama yer alır.
Lazy writes
Önce lokal veri kaynağına yazın, ardından en uygun zamanda network’e bildirmek için yazma işlemini kuyruğa alın. Uygulama tekrar çevrimiçi olduğunda network ve lokal veri kaynakları arasında çakışmalar olabileceğinden bu önemsiz bir işlem değildir. Çakışma çözümü ile ilgili bir sonraki bölümde daha fazla ayrıntı verilmektedir.
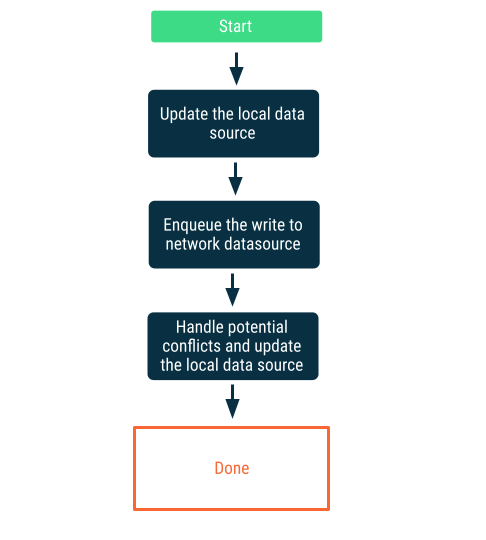
Bu yaklaşım, veriler uygulama için kritik olduğunda doğru seçimdir. Örneğin, çevrimdışı öncelikli bir yapılacaklar listesi uygulamasında, veri kaybı riskini önlemek için kullanıcının çevrimdışı olarak eklediği tüm görevlerin lokal olarak saklanması çok önemlidir.
Not: Çevrimdışı öncelikli uygulamalarda veri yazmak, olası çakışmalar nedeniyle genellikle veri okumaktan daha fazla dikkat gerektirir. Çevrimdışı öncelikli uygulamaların çevrimdışı öncelikli olarak kabul edilmesi için çevrimdışıyken veri yazabilmesi gerekmez.
Synchronization and conflict resolution
Çevrimdışı öncelikli bir uygulama bağlantısını geri yüklediğinde, lokal veri kaynağındaki verileri network veri kaynağındaki verilerle bağdaştırması gerekir. Bu işleme senkronizasyon denir. Bir uygulamanın network veri kaynağıyla senkronize olmasının iki ana yolu vardır: 1-Pull-based synchronization, 2-Push-based synchronization
- Pull-based synchronization
Pull-based senkronizasyonda uygulama, talep üzerine en son uygulama verilerini okumak için network’e ulaşır. Bu yaklaşım için yaygın bir heuristic yontem, uygulamanın verileri yalnızca kullanıcıya sunmadan hemen önce aldığı navigation-based’dir.
Bu yaklaşım, uygulamanın network bağlantısının olmadığı kısa veya ara dönemler beklediği durumlarda en iyi sonucu verir. Bunun nedeni, veri yenilemenin fırsatçı olması ve uzun süreli bağlantısızlık durumlarında kullanıcının eskimiş ya da boş bir önbellekle uygulama hedeflerini ziyaret etmeye çalışması olasılığının artmasıdır.
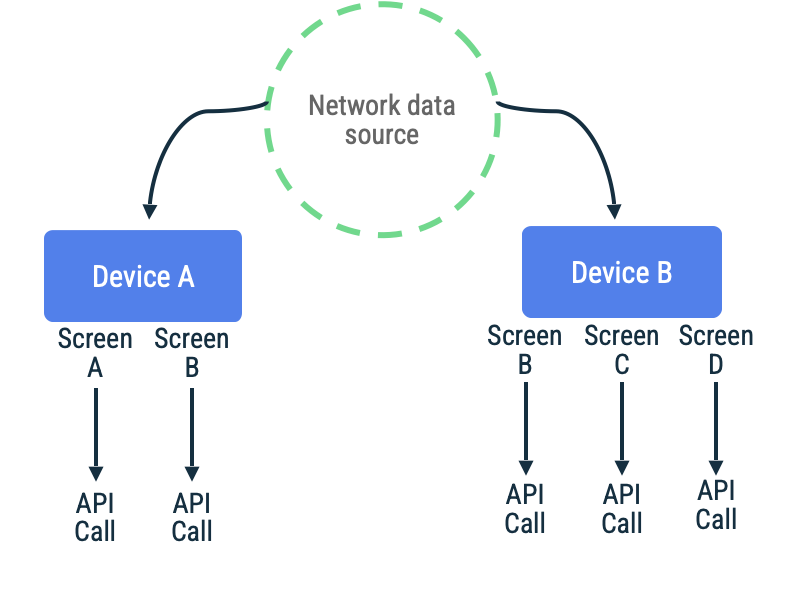
Belirli bir ekran için sonsuz kaydırma listesindeki öğeleri getirmek üzere sayfa token’larının kullanıldığı bir uygulama düşünün. Uygulama lazy bir şekilde networke ulaşabilir, verileri lokal veri kaynağında kalıcı hale getirebilir ve daha sonra bilgileri kullanıcıya geri sunmak için lokal veri kaynağından okuyabilir. Network bağlantısının olmadığı durumlarda, repository sadece lokal veri kaynağından veri talep edebilir. Bu, Jetpack Paging Library tarafından RemoteMediator API‘si ile kullanılan modeldir.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Pull Based senkronizasyonun avantaj ve dezavantajları aşağıdaki tabloda özetlenmiştir:
| Avantaj | Dezavantaj |
|---|---|
| Uygulaması nispeten kolay. | Yoğun veri kullanımına yatkındır. Bunun nedeni, bir navigasyon hedefine tekrarlanan ziyaretlerin, değişmeyen bilgilerin gereksiz yere yeniden alınmasını tetiklemesidir. Bunu uygun önbellekleme ile azaltabilirsiniz. Bu, cachedIn operatörü ile UI katmanında veya bir HTTP önbelleği ile network katmanında yapılabilir. |
| İhtiyaç duyulmayan veriler asla getirilmeyecektir | Çekilen modelin kendi kendine yeterli olması gerektiğinden ilişkisel verilerle iyi ölçeklenmez. Senkronize edilen model, kendisini doldurmak için getirilecek diğer modellere bağlıysa, daha önce bahsedilen yoğun veri kullanımı sorunu daha da önemli hale gelecektir. Ayrıca, üst modelin repository’leri ile iç içe geçmiş modelin repository’leri arasında bağımlılıklara neden olabilir. |
- Push-based synchronization
Push based senkronizasyonda, lokal veri kaynağı network veri kaynağının bir replika setini elinden geldiğince taklit etmeye çalışır. Bir baseline belirlemek için ilk başlangıçta proaktif olarak uygun miktarda veri çeker, daha sonra bu veriler eskidiğinde kendisini uyarması için sunucudan gelen bildirimlere güvenir.
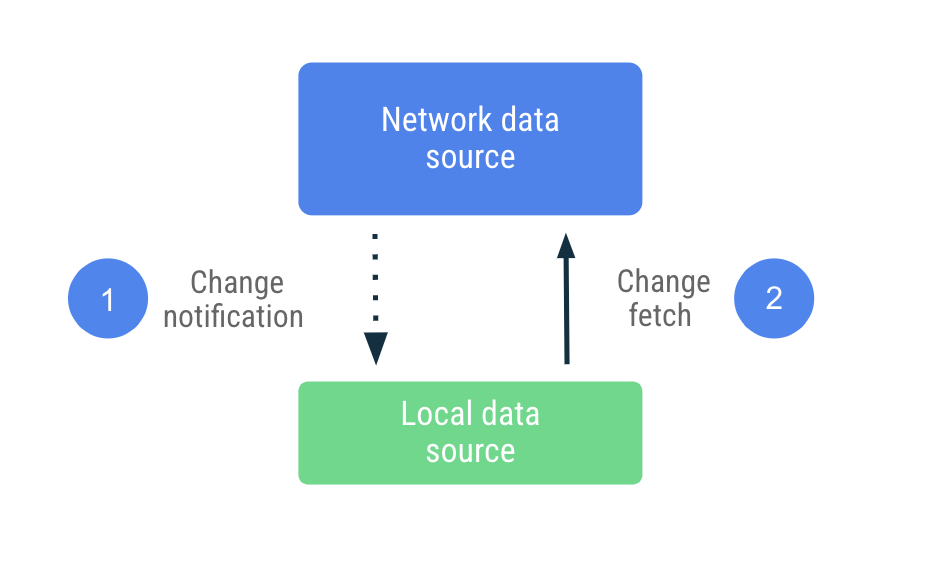
Eskimiş bildiriminin alınmasının ardından uygulama, yalnızca eskimiş olarak işaretlenen verileri güncellemek için network’e ulaşır. Bu iş, network veri kaynağına ulaşan ve lokal veri kaynağına getirilen verileri kalıcı hale getiren Repository’ye devredilir. Repository verilerini gözlemlenebilir tiplerle sunduğundan, okuyucular herhangi bir değişiklikten haberdar edilecektir.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
Bu yaklaşımda, uygulama network veri kaynağına çok daha az bağımlıdır ve uzun süreler boyunca onsuz çalışabilir. Çevrimdışıyken hem okuma hem de yazma erişimi sunar çünkü lokal olarak network veri kaynağından en son bilgilere sahip olduğu varsayılır.
Push based senkronizasyonun avantajları ve dezavantajları aşağıdaki tabloda özetlenmiştir:
| Avantaj | Dezavantaj |
|---|---|
| Uygulama süresiz olarak çevrimdışı kalabilir. | Çakışma çözümü için verilerin versiyonlanması önemsizdir. |
| Minimum veri kullanımı. Uygulama yalnızca değişen verileri alır. | Senkronizasyon sırasında yazma endişelerini dikkate almanız gerekir. |
| İlişkisel veriler için iyi çalışır. Her repository yalnızca desteklediği model için veri getirmekten sorumludur. | Network veri kaynağının senkronizasyonu desteklemesi gerekir. |
- Hybrid synchronization
Bazı uygulamalar, verilere bağlı olarak pull veya push based olan hibrit bir yaklaşım kullanır. Örneğin, bir sosyal medya uygulaması, akış güncellemelerinin yüksek sıklığı nedeniyle kullanıcının takip akışını talep üzerine almak için pull based senkronizasyon kullanabilir. Aynı uygulama, kullanıcı adı, profil resmi vb. dahil olmak üzere oturum açan kullanıcı hakkındaki veriler için push based senkronizasyonu kullanmayı tercih edebilir.
Sonuç olarak, çevrimdışı öncelikli senkronizasyon seçimi ürün gereksinimlerine ve mevcut teknik altyapıya bağlıdır.
Not: Uygulamanızın senkronizasyon yöntemi, uygulamanızın ihtiyaçlarına ve lokal ve network veri kaynaklarını destekleyen altyapının kısıtlamalarına bağlıdır.
Conflict resolution
Uygulama çevrimdışıyken lokal olarak network veri kaynağıyla uyumsuz veri yazıyorsa, senkronizasyon gerçekleşmeden önce çözmeniz gereken bir çakışma meydana gelmiştir.
Çakışma çözümü genellikle versiyonlama gerektirir. Uygulamanın, değişikliklerin ne zaman gerçekleştiğini takip etmek için bazı kayıt tutma işlemleri yapması gerekecektir. Bu, meta verileri network veri kaynağına aktarmasını sağlar. Network veri kaynağı daha sonra source of truth sağlama sorumluluğuna sahiptir. Uygulamanın ihtiyaçlarına bağlı olarak çakışma çözümü için dikkate alınması gereken çok çeşitli stratejiler vardır. Mobil uygulamalar için yaygın bir yaklaşım “son yazan kazanır(last write wins) “dır.
- Last write wins
Bu yaklaşımda, cihazlar network’e yazdıkları verilere zaman damgası metadatası eklerler. Network veri kaynağı bunları aldığında, mevcut state’inden daha yeni olanları kabul ederken mevcut state’inden daha eski olan verileri reddeder.
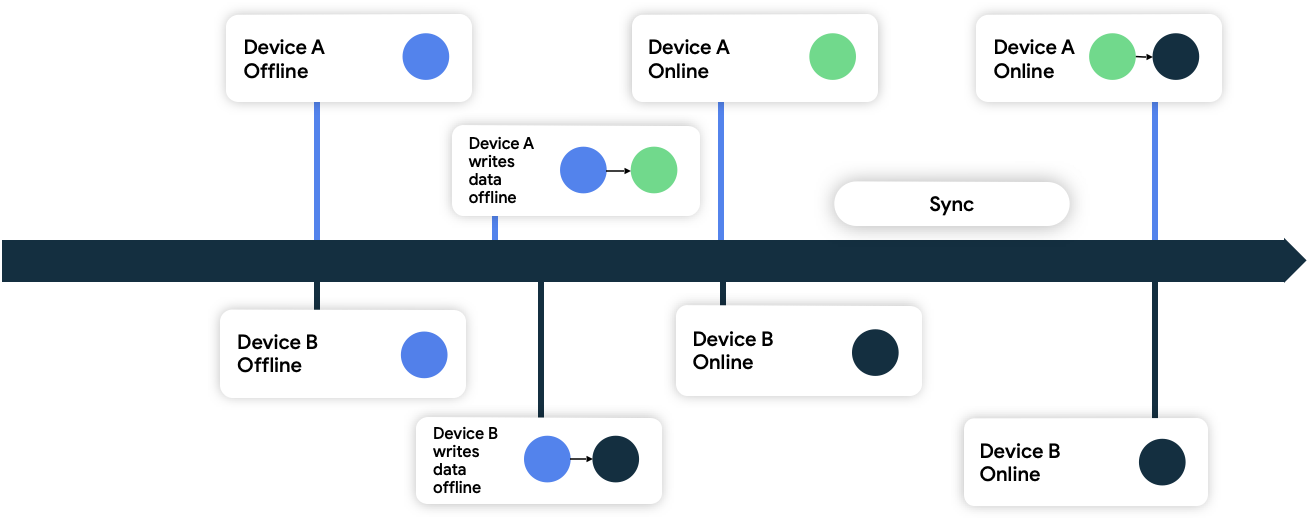
Yukarıdaki şekilde, her iki cihaz da çevrimdışıdır ve başlangıçta network veri kaynağı ile senkronizedir. Çevrimdışıyken, her ikisi de lokal olarak veri yazar ve verilerini yazdıkları zamanı takip ederler. Her ikisi de tekrar çevrimiçi olduğunda ve network veri kaynağı ile senkronize edildiğinde, network, B cihazının verilerini daha sonra yazdığı için bu cihazın verilerini kalıcı hale getirerek çakışmayı çözer.
WorkManager in offline-first apps
Yukarıda ele alınan okuma ve yazma stratejilerinin her ikisinde de iki ortak araç vardı:
- Queues
- Reads: Network bağlantısı mevcut olana kadar okumaları ertelemek için kullanılır.
- Writes: Network bağlantısı mevcut olana kadar yazmaları ertelemek ve yeniden denemeler için yazmaları yeniden istemek için kullanılır.
- Network connectivity monitors
- Reads: Uygulama bağlandığında okuma kuyruğunu boşaltmak ve senkronizasyon için bir sinyal olarak kullanılır
- Writes: Uygulama bağlandığında yazma kuyruğunu boşaltmak ve senkronizasyon için bir sinyal olarak kullanılır
Her iki durum da WorkManager’ın üstün olduğu persistent work örnekleridir. Örneğin Now in Android örnek uygulamasında, WorkManager lokal veri kaynağını senkronize ederken hem okuma kuyruğu hem de ağ monitörü olarak kullanılır. Başlangıçta, uygulama aşağıdaki eylemleri gerçekleştirir:
- Lokal veri kaynağı ile network veri kaynağı arasında eşitlik olduğundan emin olmak için okuma senkronizasyon işini kuyruga alın.
- Okuma senkronizasyon kuyruğunu boşaltın ve uygulama çevrimiçi olduğunda senkronize etmeye başlayın.
- Network veri kaynağından exponential backoff kullanarak bir okuma gerçekleştirin.
- Okuma sonuçlarını, oluşabilecek çakışmaları çözerek yerel veri kaynağına aktarın.
Lokal veri kaynağındaki verileri uygulamanın diğer katmanlarının kullanması için sunun.
- Yukarıda anlatılanlar aşağıdaki şemada gösterilmiştir:
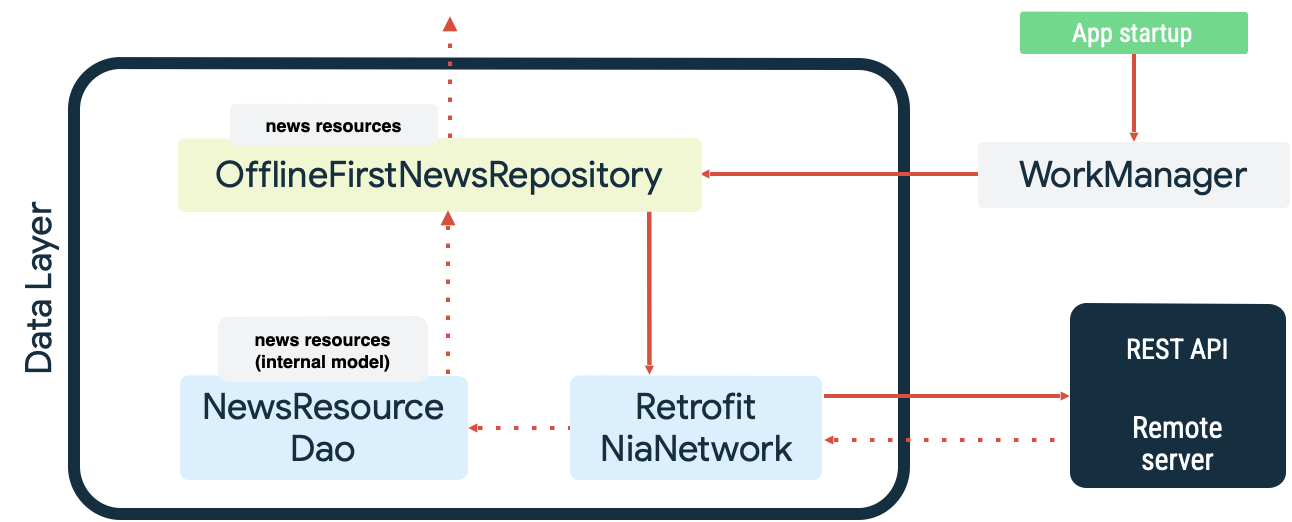
WorkManager ile senkronizasyon işinin kuyruğa alınması, KEEP ExistingWorkPolicy ile benzersiz iş olarak belirtilerek takip edilir:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
Not: “Now in Android “deki okuma kuyruğu sadece enqueueUniqueWork API’si ile temsil edilebilecek kadar basittir. Kuyruğun boşaltılma sırası hakkında daha sıkı garantiler için, Room veya Datastore gibi bir veri kalıcılığı API’si ile daha sağlam bir kuyruk uygulamasının gerçekleştirilmesi gerekecektir. Daha sonra bu kuyruğu sırayla boşaltmak için bir Worker ayarlanabilir.
Burada SyncWorker.startupSyncWork() aşağıdaki gibi tanımlanır:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Özellikle, SyncConstraints tarafından tanımlanan Kısıtlamalar(Constraints) NetworkType‘ın NetworkType.CONNECTED olmasını gerektirir. Yani, çalışmadan önce network kullanılabilir olana kadar bekler.
Network kullanılabilir olduğunda, Worker uygun Repository instance’larına temsilci atayarak SyncWorkName tarafından belirtilen benzersiz iş kuyruğunu boşaltır. Senkronizasyon başarısız olursa doWork() metodu Result.retry() ile döner. WorkManager, exponential backoff ile senkronizasyonu otomatik olarak yeniden deneyecektir. Aksi takdirde, senkronizasyonu tamamlayarak Result.success() döndürür.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}